框架和使用场景
概念:解决分布式系统数据一致性问题,是一个拥有文件系统特点的数据库。
特点:一致、有头、数据树 。
场景:数据发布订阅、负载均衡、注册中心、HA(HDFS中的NN)
使用方法
node:永久、临时
1.拷贝到多台机器,解压
2.配置(多台机器)
Conf zoo_sample.cfg server.1=ip1+两个端口号 server.2=ip2 server.3=ip3
3.执行 /bin ./zkserver.sh start启动 status
4.客户端连接集群 bin/zkCli.sh -server node0:端口
5.在里面放数据,进行增删改查
新建节点,及节点对应data :create /app appinfo、create /app/config appconfig 、get /app、set /app appinfo2
6.提供了一个API,让外部应用在这些节点上增删改查
集群节点数:推荐奇数。3台和4台,都只能挂掉1台,两者容错性一致。
运行机制
fastleaderelection选举机制
选举时间:集群启动、leader挂掉、follow挂掉后leader发现没有一半节点跟随自己
名词:服务器id 、选举状态 looking 、数据id(数据越新权重越大)
全新集群:(主要参考服务器的编号)
1. 每个机器都给自己投票 数组[] 2. 投票数过半,选举结束
例子:1、2、3、4、5号机器顺序启动,如下图。
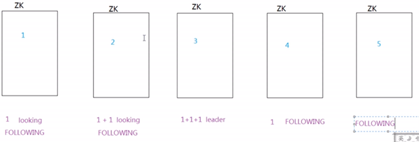
假设5台服务器,每台服务器没有数据,按12345编号顺序启动,选举过程如下:
1启动:给自己投票,发投票信息,其他服务器未启动,处于looking状态
2启动:给自己投票,与1交换结果,由于2大于1,2胜出,此时投票数未超过一般,皆为looking状态
3启动:给自己投票,与1,2交换信息,3胜出,投票数大于一般,成为leader
4启动:给自己投票,与1,2,3交换结果,尽管编号大,但是3已经为leader;
5启动:同4.
非全新集群(此时不能单单靠服务器id判断,因为集群已经运行一段时间了)
对于运行正常的集群,中途有机器down掉,需要重新选举时,选举过程需要加入数据ID(数据新的version大),服务器ID,逻辑时钟(从0递增,每次选举对应一个值,如果在同一次选举中,这个值是一致的)。
leader选举标准:
1.逻辑时钟小的选举结果忽略,重新投票;
2.统一逻辑时钟后,数据ID大的胜出;
3.数据ID相同的情况下,服务器ID大的胜出。
ZAB协议
只允许leader进行事务处理;
为follower创建队列,在队列中向其他节点广播提案,follower收到后发送ack;
Leader收到一半以上响应后,向节点发送commit消息,leader提交该提案。
Paxos算法
概念:基于消息传递且具有高度容错性的算法,解决在分布式系统中如何就一个值达成统一。存在机器宕机或者网络异常情况下,快速正确地对某个数据的值保持一致。
角色:proposer、acceptor、learner
数学原理:超过半数进程组成的集合为法定集合,两个法定进程至少有一个公共进程。
过程:prepare+accept
Prepare:proposer提出编号为m的提案,发送prepare请求给accept集合,acceptor做出反馈,如果accpetor之间批准过提案,则返回一个最大提案值,同时不会再接收比M小的提案;如果proposer收到集合至少一半的响应,则发送针对M的accept请求给acceptor,。
Accept:acceptor收到accept请求后,只要未收到任何编号大于M的prepare请求,则通过提案。
一致性模型
- 弱一致性 最终一致性
- 强一致性 (主从同步、Paxos、ZAB)【method1:减少同步时间;method2:加锁,降低了可用性】
CAP理论
强一致性、可用性、分区容错性 (三者只能同时满足两个)案例:钱财安全满足CP,用户体验满足AP,ZK满足CP
案例:服务器列表动态更新
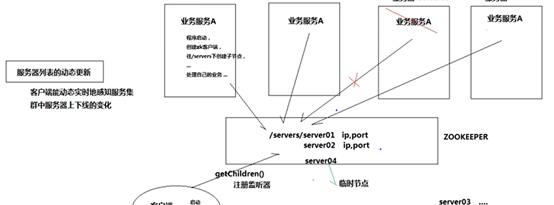
客户端操作
当客户端发写请求给follower:follower会转发请求给leader。
当多个客户端发送请求(并发):queue+单线程 让事务ID自增
读操作直接从follower读取,很快,写会慢。
新增Observer节点:用于提高读操作,不参与投票,leader会在commit阶段同步observer数据。对写操作略有影响。
源码分析
